2024.02.29_学习日记
天气:雨
学习地点:学校
学习时长:10h
学习内容
- 机器学习在管理学上的应用
生成有价值的信息,比如生成性格特质,大五人格模型的特质,作为自变量。可以做一个验证实验,来预测该机器学习方法能不能很好预测生成特质的信息。
预测。添加一些机器学习生成的特质到模型里去,对比原模型和新模型的预测能力差别。
因果推断,略。
机器学习的研究方法主要就是生成一些特征,下一步需要弄清楚怎么生成特征。
《管理者短视主义影响企业长期投资吗?——基于文本分析和机器学习》文章中用机器学习方法生成了管理者是否短视这个特征。通过别的论文的种子词汇,然后用word2vec扩展相似词,然后看所有词词频占所有词词频比例,得到一个指标用来衡量管理者是否短视。

《数字化转型、竞争战略选择与…于机器学习与文本分析的证据》这篇文章也用相似方法生成企业竞争战略指标,通过数字化转型的不同层面统计词频然后生成数字化转型的指标。 - lc32

这个题跟最长子串子数组一样,就是用一个dp数组,算以当前为结尾最长括号的个数,最后返回max(dp)即可,如果当前为),前一个为(,那就返回dp【i-2】+当前括号2.如果前一个是),那前面就一定有一段有效长度,i-dp【i-1】-1位置上如果是(,那就看i-dp【i-1】-2位置,如果存在那就加上这个位置的dp值,再加2,如果不存在,那就是上一个位置+2。
还有栈的方法,from collections import deque,返回栈顶元素是deque【-1】。核心思想先放入-1入栈,因为如果一开始是(进去,如果弹出左括号,返回i-栈顶元素应该是2,所以最开始的值放-1进去。如果左括号入栈,右括号就弹出栈顶元素并且i-新栈顶元素,如果弹出后栈为空,那就把右括号入栈。最后返回最大值。 - 栈队列互相实现
栈实现队列:用两个栈,一个push栈,一个pop栈,用户输入123,要返回123,先把123放入push栈,如果pop栈没东西,就把push栈全部放入pop栈,pop栈就是321,然后再从pop栈里弹出就是队列方法输入123。
队列实现栈:两个队列,先放入123,输出也会是123,但是如果要pop的话,就把12弹出到另一个队列里,然后弹出剩下的3就能实现栈的pop方法。
图的宽度优先遍历只能用队列实现,图的深度优先遍历只能用栈来做,但是栈和队列可以互相改。 - 接雨水lc42
有一个新的解法,就是双指针,左右两边分别生成最大值,如果当前位置大于左右两边值的最小值,那就为0,并且更新最大值,指针相应移动,如果小于,ans就加上差值,最后返回ans。 - 洗咖啡杯问题
首先用一个小根堆把(开始泡咖啡时间,泡咖啡需要的时间)按照这两个值之和排序,遍历数组,每次弹出小根堆堆顶,并且更新开始泡咖啡时间,然后重新放入小根堆,用一个tmp数组,记录每个人泡完的时间,最后生成数组。该数组再用动态规划思想,basecase就是当index==数组长度时,返回min(max(洗杯子时间,tmp【index】)+洗杯子的时间a,蒸发时间b+tmp【index】),然后wash=max(洗杯子时间,tmp【index】)+洗杯子的时间a),即什么时候洗完杯子,next1=递归(index+1,wash),p1=这两种情况的最大值。dry=蒸发时间b+tmp【index】,next2=递归(index+1,washline即初始wash时间),p2=这两种情况最大值,最后返回min(p1,p2).
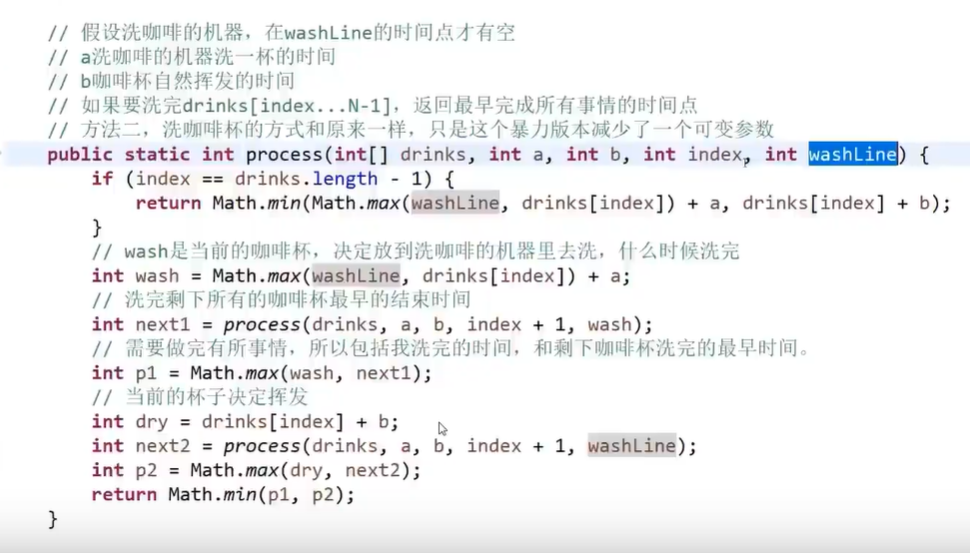
- 算法题

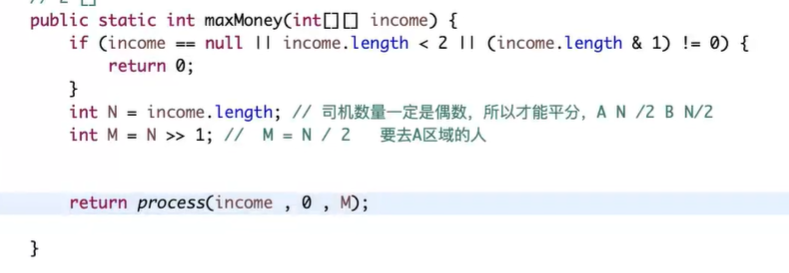

先分成两组,如果长度是奇数,返回0.然后递归动态规划,index到长度,返回0。还剩下司机的话,如果长度-index刚好等于rest,那就只能等分到A组,如果index到长度了,rest还有,那就只能分到B组,递归就行。如果都可以去,那就分别递归,返回最大值即可。 - lc135分发糖果

之前做过,就是两个数组,left数组表示如果右边值比左边大就+1,否则就=1,right就是相反,最后返回两个数组最大值的和即可。 - lc97

这个题不能用双指针,因为如果字符一样就没法判断总字符串来自哪里,只能用动态规划,样本对应模型,dp表表示当s1用i个数字,s2用j个数字,能否凑出s3的i+j个字符,第一行和第一列就是如果当前位置能否完全由s1或者s2前n个数字拼凑出来,当遇到不能拼出来的时候,后面就全是False,其他位置的依赖是,ij位置的值等于如果s3当前位置等于s1位置,并且i-1j位置为True,或者等于s2位置时,ij-1位置为True,那就返回tRUE,最后返回dp【-1】【-1】。