2024.02.28_学习日记
天气:雨
学习地点:学校
学习时长:10h
学习内容
- 机器学习
K-means聚类方法:
二分 K-Means 不急于一来就随机 K KK 个聚类中心,而是首先把所有点归为一个簇,然后将该簇一分为二。计算各个所得簇的失真函数(即误差),选择误差最大的簇再进行划分(即最大程度地减少误差),重复该过程直至达到期望的簇数目。虽然二分 K-Means 能带来全局最优解,但是我们也可以看到,该算法是一个贪心算法,因此计算量不小。
CA,Principle Component Analysis,即主成分分析法,是特征降维的最常用手段。顾名思义,PCA 能从冗余特征中提取主要成分,在不太损失模型质量的情况下,提升了模型训练速度。把高纬度降到低纬度。
- LC517

这个题的思路是,先计算出每个洗衣机平均需要多少衣服,然后遍历数组,当前位置左边和右边分别需要多少衣服,或者需要给两边多少衣服,如果左右两边都需要衣服,那就更新ans=左右两边衣服数量相加和ans的最大值,如果两边都大于0,或者有一边大于0,那就等于左右两边值的最大值和ans最大值,不要忘记每次要更新左边的和。 - 螺旋遍历二维数组

把左上右下两个角标记出来,最后螺旋完以后会出现两种情况,一种是还剩一行,一种是还剩一列,这两种分别打印完就行,核心思想是先遍历上面,再右边,再下面,再左边,每次打印到倒数第二个值就行,用currow和curcol去遍历,然后遍历完一圈后,左上右下两个角要动一下,直到while条件结束为止,这个题一定要看是否越界!! - lc48旋转图像

跟上面这个题类似,先打印外圈再打印内圈,打印外圈的时候,把它们分为不同组,每个边框取一个位置变成一个组,然后有多少组就循环多少次,每一次直接换位置就行,然后主函数里把对角线两个点的位置信息要更新,while循环也要注意条件。 - 小根堆解法

用一个容量为k的小根堆,遍历整个数组放进哈希表里,然后把哈希表所有数字放进小根堆比较它是否比小根堆堆顶大,如果更大,那就弹出堆顶,然后放进去,最后就能生成topK。 - lc3

看到这种子串、子数组之类的题,就想到以当前位置结尾,最长子串长度是多少,然后生成一个数组,返回这个数组最大值即可。每到一个位置,就可以想当前位置的值能不能由前一个位置的值得到。当前位置的数字上一次出现的位置,还有前一个位置的值.用一个哈希表记录每个位置的字符上次出现的位置,每到一个位置,看这个位置的字符在不在哈希表里,不在的话p1=i+1,在的话就p1=i-前一个位置哈希值,p2=pre+1,pre的意思就是前一个位置的字符的p值,pre要一直更新,从第一个位置往后一直更新,pre每次要更新成cur,hash表上一次当前位置的值也要更新成当前的i位置。 - lc494


最简单的方法就是用一个函数,变量为index和rest值,当index到arr长度时,如果rest为0,就返回1。最后返回当前值为正和为负的递归值。更好的办法是有几个优化点,首先sum如果小于target,返回0。其次如果target和sum奇偶性不同返回0,否则返回能凑出t+sum/2的方法数,这个是数学推导出来的。记得考虑target是否为复数。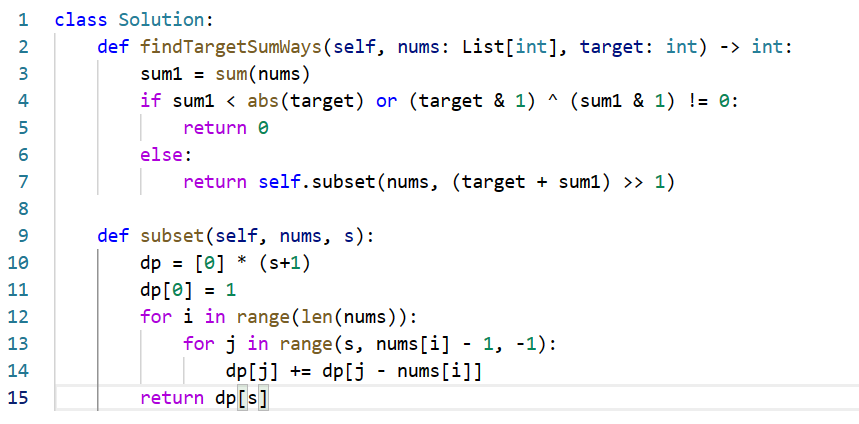
好好看看这段代码。